ページの先頭です
- ページ内移動用のリンクです
- ホーム
- IIJの技術
- セキュリティ・技術レポート
- Internet Infrastructure Review(IIR)
- Vol.63
- 2. フォーカス・リサーチ(1)W3C標準化活動:RDF Dataset Canonicalization
Internet Infrastructure Review(IIR)Vol.63
2024年6月
- 目次
2. フォーカス・リサーチ(1)
W3C標準化活動:RDF Dataset Canonicalization
2.1 はじめに
本稿では、筆者がWorld Wide Web Consortium(W3C)で標準化に協力し、2024年5月にW3C勧告となったばかりのRDF Dataset Canonicalization(注1)について紹介します。RDF Dataset Canonicalization は、Resource Description Framework(RDF)で表現されたデータを正規化する仕組みです。以降では、RDFがどのようなものであるか、そしてRDFの正規化とはどんな処理であるか、更にどういった場面でそれが必要とされるのかを説明します。また、W3Cにおける標準化活動の経緯や、具体的な正規化の手順についても説明します。
2.2 RDFとは
RDFはWeb上の情報(リソース)を記述するためのフレームワークとして、W3Cで標準化されたものです。RDFを使うことで、異なるデータベースやアプリケーションの間でデータを簡単に連携できるようになります。そのため、生命科学、薬学、図書館などの分野で広く使われています。1999年に初版がW3C勧告となり、その後2004年にRDF 1.1(注2)が勧告となりました。本稿執筆時(2024年5月)はRDF 1.2(注3)の標準化が行われている最中です。
RDFは、情報を「主語」「述語」「目的語」の3つの要素で表現します。この3つの組はRDFトリプルと呼ばれます。例として、日本の様々なコンテンツを検索できるジャパンサーチ(注4)から取得した、枕草子に関するRDFトリプルを以下に示します。
- 主語:<https://jpsearch.go.jp/data/bibnl-20853658>
- 述語:<http://www.w3.org/2000/01/rdf-schema#label>
- 目的語:"枕草子:対訳"
RDFトリプルは一般的な文と同様に、「主語の述語は目的語である」と読むことができます。このRDFトリプルが表しているのは「...bibnl-20853658の...labelは枕草子:対訳である」という文であるといえます。ここで、主語<https://jpsearch.go.jp/data/bibnl-20853658>は、ジャパンサーチがある図書に割り当てた識別子です。述語<http://www.w3.org/2000/01/rdf-schema#label>はW3CのRDFスキーマ(注5)で定められた用語で、この後に来る目的語"枕草子:対訳"が、主語のラベル(簡単な説明文)であることを意味しています。つまりこのRDFトリプルは、識別子<https://jpsearch.go.jp/data/bibnl-20853658>を持つ情報に"枕草子:対訳"というラベルが付くことを表しています。
このようにRDFトリプルでは<https://jpsearch.go.jp/data/bibnl-20853658>のようなURL(注6)で多くの情報を表現します(注7)。URLを使うのは、データの作成者が表現しようとしている情報を正確に伝えるためです。もし主語と述語がURLを使わず、単に20853658、labelと表されていた場合、20853658がどこで定められた識別子なのか、またlabelという述語の意味が何であるか、読み手が正しく理解するのは難しくなってしまうことでしょう。
RDFトリプルは、図-1のように2つのノード(丸や四角で囲まれた情報)を矢印で繋いだ図として描かれることもあります。図-1では読みやすさを考慮して、URLの一部https://jpsearch.go.jp/data/をdata:という省略形に書き換えています。同様にhttp://www.w3.org/2000/01/rdf-schema#はrdfs:で置き換えています。以降でもこのような短縮表記を使います。
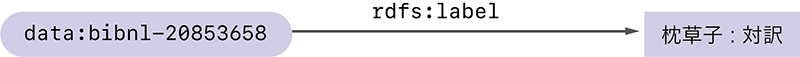
図-1 枕草子に関するRDFトリプルの例
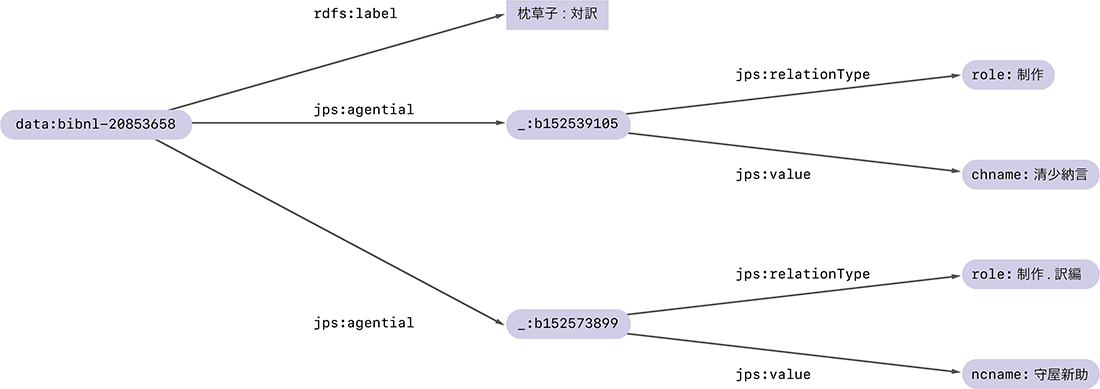
RDFトリプルを集めたものはRDFグラフと呼ばれます。先程と同様、枕草子に関するRDFトリプルをジャパンサーチから追加で取得すると、図-2のようなRDFグラフを作ることができます。
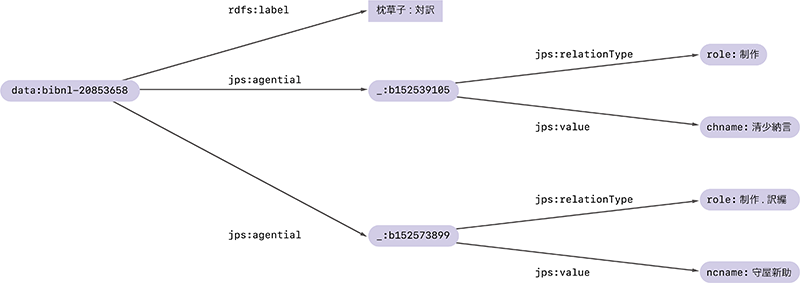
図-2 枕草子に関するRDFグラフ
このRDFグラフでは、data:bibnl-20853658のラベルが「枕草子:対訳」であることに加えて、その制作に関わった人が清少納言であることと、訳編に関わった人が守屋新助であることが表されています。
RDFトリプルを集めたものがRDFグラフでしたが、RDFグラフを集めたものはRDFデータセットと呼ばれます。本稿のテーマであるRDF Dataset Canonicalizationはその名のとおり、RDFデータセットを正規化する方法です。ただし本稿では説明を簡単にするため、RDFグラフとRDFデータセットを区別せずに扱います。
2.3 RDFの空白ノード
図-2の例にはおもむろに_:b152539105や_:b152573899という奇妙な名前のノードが登場しました。これらは空白ノード(blank node)と呼ばれる、識別子(URL)を持たない特殊なノードです。巨大なRDFグラフを作る際など、すべてのノードにURLを付けるのはときに煩雑な作業になります。そこで、他のグラフとは繋がることのない中間的なノードなどには、URLをもたない空白ノードが使われることがあります。
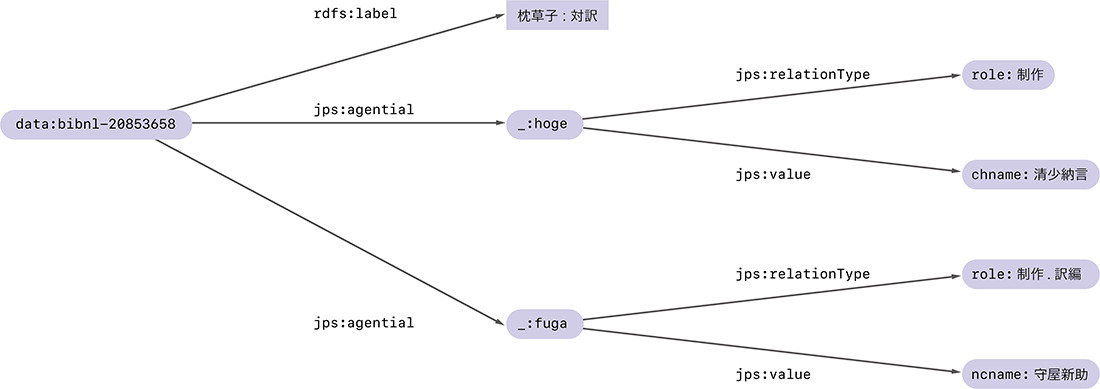
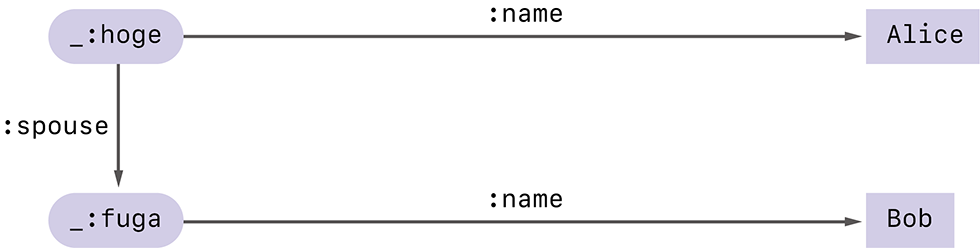
空白ノードに付けられた名前は、あくまで一時的な名前です。同じRDFグラフでも、扱うシステムや環境によって、空白ノードの名前は変わってしまうことがあります。例えば上の_:b152539105と_:b152573899をそれぞれ_:hogeと_:fugaに置き換えた図-3のRDFグラフは、置き換え前のRDFグラフと同じものとして(正確には同型なグラフとして)扱われます。
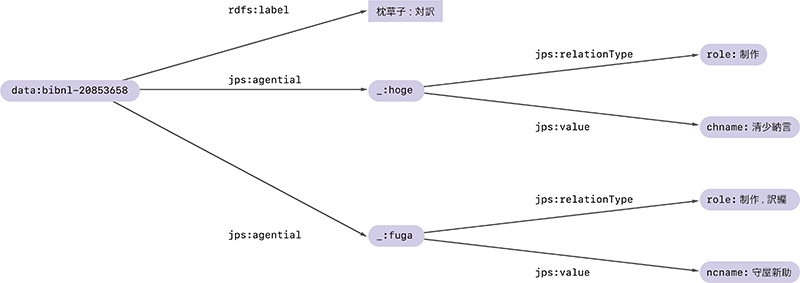
図-3 枕草子に関するRDFグラフのもう1つの例
そのおかげで、RDFグラフの作成者は空白ノードの名前付けに頭を悩ませる必要がなくなるという利点があります。また、RDFグラフをデータ化するときにそれらを省略できるというメリットもあります。例えば、図-3のRDFグラフはJSON-LD(注8)という仕様を使うと次のように表せます。ここでは空白ノードの名前を意識する必要がなくなっています。

2.4 Canonicalization(正規化)
便利な空白ノードですが、決まった名前を持たないという特徴が問題を生むこともあります。例えば、2つのRDFグラフが同じグラフであるか確認したい場合や、グラフとグラフの差分を知りたい場合、またあるRDFグラフに更新があったか知りたい場合などに、この空白ノードの扱いが問題となってきます。また、RDFグラフに作成者のデジタル署名を付ける場合、署名を付けたときの空白ノードの名前と、それを後に検証するときの空白ノードの名前が一致していなければ検証に失敗してしまいますが、それは空白ノードの性質上保証されません。
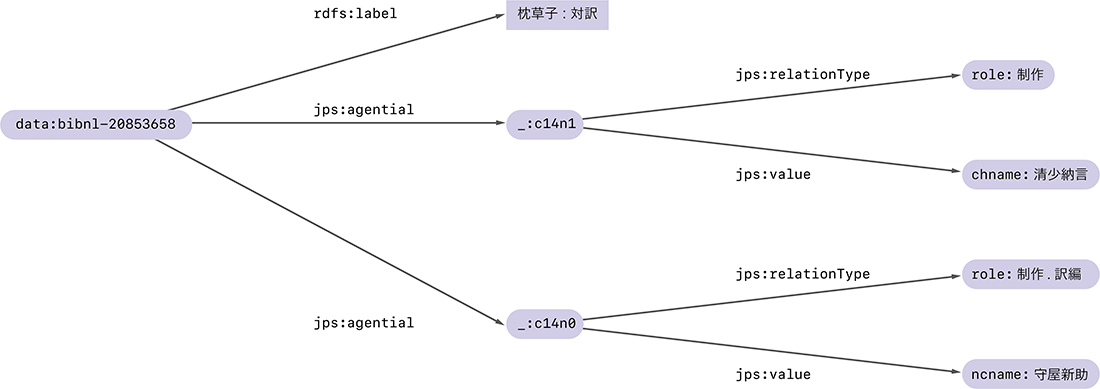
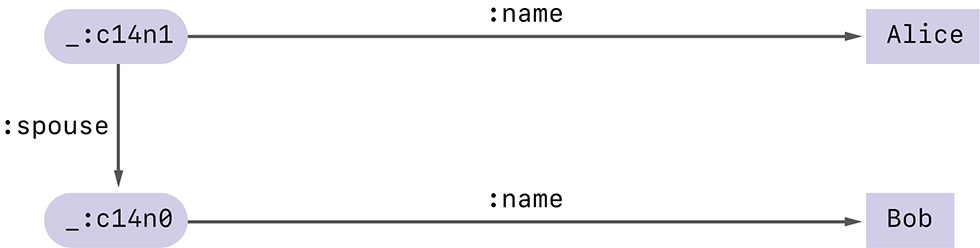
そこで、システムや環境によらず、名前を持たない空白ノードに決まった名前を付ける方法が必要となりました。それが今回のテーマであるRDF Dataset Canonicalizationです。例えば図-2と図-3に登場した2つのRDFグラフは、Canonicalizationを行うことでどちらも同じ図-4のグラフに変換されます。
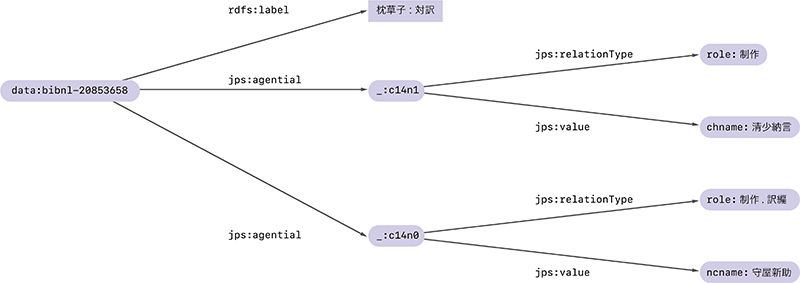
図-4 Canonicalizationを行ったRDFグラフの例
Canonicalization後の空白ノードには_:c14n0、_:c14n1という新しい名前が与えられます(注9)。これらは、元々空白ノードに付けられていた_:b152539105や_:hogeといった値には左右されず、グラフに現れるURLや文字列と、グラフの構造に基づいて、決まった方法で計算されます。従って元の空白ノードにどのような名前が付けられていたとしても同じグラフを得ることができるわけです。
空白ノードの名前が確定したところで、後はこれをCanonical N-Quadsと呼ばれる形式(注10)で出力すれば、図-5のような正規化されたデータを得ることができます。正規化後のデータを使うことで、RDFグラフの差分計算や更新の確認、デジタル署名やハッシュ値の計算が簡単に実現できます。
本レポートのVol.52(https://www.iij.ad.jp/dev/report/iir/052.html)(注11)で取り上げたW3C Verifiable Credentialというデジタル証明書は、デジタル署名のついたRDFデータセットです。デジタル署名をつける前に、このRDF Dataset Canonicalizationを使って空白ノードの名前を正規化することで、署名するデータと検証するデータが同じになることを保証しています。
2.5 標準化活動
標準化には得てして長い時間がかかります。RDF Dataset Canonicalizationの標準化にも10年以上もの長い歳月が費やされました。議論自体は早い段階から始まっていたものの、標準化の必要性や最適な方法についてのコンセンサスが長らく得られなかったことが一因です(注12)。
まず2009年から2010年にかけてW3CでCanonicalizationの仕様化に関する議論が始まりました。2012年には、Digital Bazaar社のDave LongleyとManu SpornyがUniversal RDF Graph Normalization Algorithm(URGNA2012)を提案しました。更にその3年後には、改訂版であるUniversal RDF Dataset Normalization Algorithm(URDNA2015)が提案され、今回標準化された仕様のベースとなりました。
その後、W3C内でVerifiable Credentialの議論が活発になり、2021年にはRDFデータにデジタル署名を付けるためのLinked Data Signatures Working Groupの立ち上げが提案されました。しかし、署名プロセス全体の標準化に関しては合意形成に至らず、中止となりました。その代替案として、RDF の正規化に焦点を当てたRDF Dataset Canonicalization and Hash Working Group(RCH WG)(注13)が提案され、2022年7月に承認されました。
こうしてようやく、RDF CanonicalizationをW3C勧告とするための作業が始まりました。そして2024年5月21日、標準化活動のゴールであるW3C勧告へと至ることができました(注14)。
筆者はWG Chairからの招待を受けて、2022年8月に招聘専門家(Invited Expert)としてRCH WGに参加し、同11月からはEditorとして協力しました。きっかけは、筆者らのVerifiable Credentialsに関する国際会議での発表内容(注15)がWG co-chairの目に止まったことでした。
RCH WGの活動は、GitHub上での議論と隔週の電話会議が中心です。GitHub上では問題提起や修正案の投稿が行われ、電話会議では課題の解決に向けた議論やメンバーの合意形成が行われます。その結果がGitHub上での編集活動を通じて仕様文書に反映されていきます。筆者にとっては初めての標準化活動であり、有識者の議論に付いていくのもやっとでしたが、文面の提案やPull Requestのレビュー、リファレンス実装の提供など、できることから貢献に努めました。
W3Cの仕様は、読者がその内容を正しく実装できることが重要な要件です。本稿執筆時(2024年5月)、RDF Dataset Canonicalizationには9つのオープンソース実装が寄せられており、開発言語もC++、Elixir、Java、JavaScript、Ruby、Rust、TypeScriptと多岐にわたっています(注16)。筆者もRustによるオープンソース実装を提供しました(注17)。

図-5 正規化された結果
2.6 Canonicalizationの手順
RDF Dataset Canonicalization仕様が定めるアルゴリズムはRDF Canonicalization algorithm version 1.0、通称RDFC-1.0と命名されています。本稿ではRDFC-1.0の概要を説明します。
RDFC-1.0は、入力されたRDFグラフ内の空白ノードにラベル付けをする正規化(canonicalize)と、正規化されたRDFグラフをCanonical N-Quads形式の正規化されたデータとして出力する直列化(seriarize)の2つのステップからなります。
第1の正規化のステップでは、まずグラフ内の空白ノード1つ1つについて1次ハッシュ(first degree hash)と呼ばれる値を計算していきます。これは空白ノードの周辺の情報をハッシュ関数と呼ばれる特殊な関数に入れて、長さの決まったハッシュ値と呼ばれるデータを得るものです。直観的には、空白ノードの周辺の情報を使って、その空白ノードに名前を付ける操作に相当します。
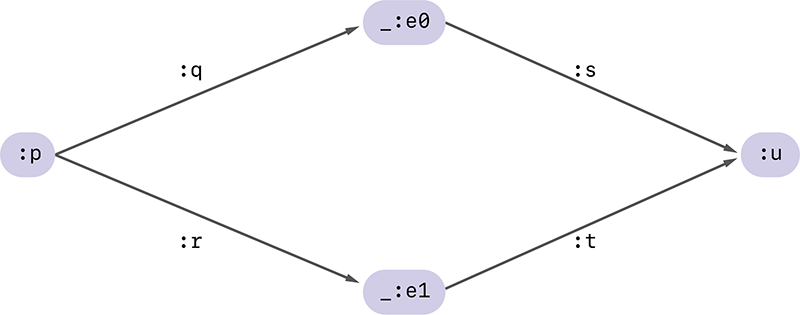
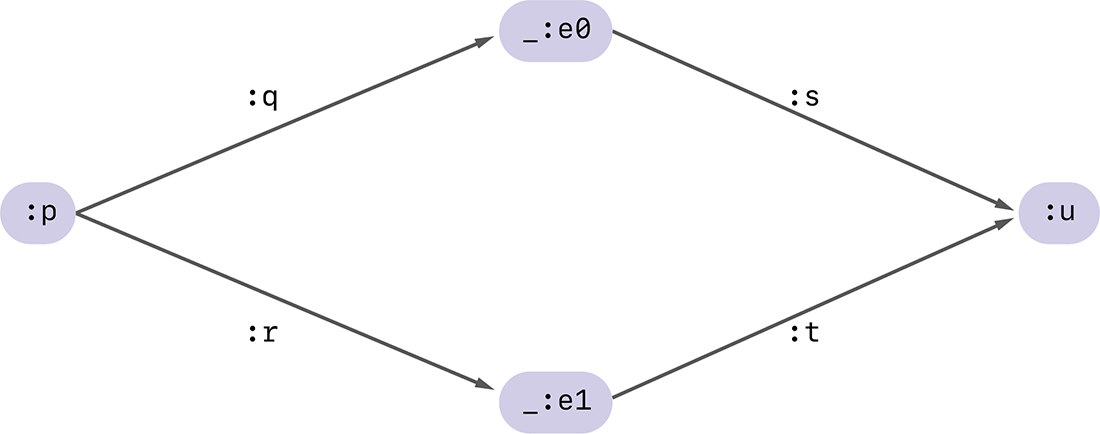
図-6 2つの空白ノードを含むRDFグラフの例
空白ノードに付けられた1次ハッシュの値がすべて異なっていれば、後はそれを辞書順(注18)に並べ直すことで、空白ノードに順番を付けることができます。この順番に従って_:c14n0, _:c14n1, _:c14n2, ...という要領でラベル付けをすれば、めでたく正規化の処理は完了です。
図-6の例を使って、具体的にこの流れを説明します。このRDFグラフは4つのノードを含み、そのうち2つ(:pと:u)がURLを持つ通常のノードで、残りの2つ(_:e0と_:e1)が空白ノードです。
ここで空白ノード_:e0を含むRDFトリプルだけを抜き出し、Canonical N-Quads形式で表すと以下のようになります。
:p :q _:e0 .
_:e0 :s :u .
これが_:e0の周辺情報に対応します。ここで空白ノードに付けられている「仮の」名前e0をaで置き換え、次の文字列を得ます。
:p :q _:a .
_:a :s :u .
これをハッシュ関数に入力し、得られたビット列を16進数で表現した21d1dd5ba21f3dee9d76c0c00c260fa6f5d5d 65315099e553026f4828d0dc77aが、空白ノード_:e0の1次ハッシュ値になります。この1次ハッシュ値には_:e0の周辺情報が埋め込まれており、_:e0と他の空白ノードを区別するために使うことができます。
同様に_:e1を含むRDFトリプルを抜き出すと
:p :r _:e1 .
_:e1 :t :u .
のようになり、先程と同様にe1をaで置き換えて得られた
:p :r _:a .
_:a :t :u .
のハッシュ値6fa0b9bdb376852b5743ff39ca4cbf7ea1 4d34966b2828478fbf222e7c764473が_:e1の1次ハッシュ値になります。
これらを辞書順で並べると、先頭が2で始まる_:e0の1次ハッシュ値の方が、先頭が6で始まる_:e1の1次ハッシュ値よりも辞書順で先に来ることが分かります。この結果、e0とe1の間に順序を定めることができました。あとはこの順序にしたがって、_:e0に_:c14n0、_:e1に_:c14n1という正規化識別子を与えれば正規化は完了です。
正規化前の空白ノードに付けられていた名前が何であっても、正規化後の結果が変わらないことが重要です。実際、図-6の例で、_:e0を_:hogeで、_:e1を_:fugaでそれぞれ置き換えても、それらの1次ハッシュ値が変わらないことが確認できます。1次ハッシュ値の計算の途中、空白ノードの名前をみなaに置き換えましたが、そのおかげで計算結果は元々付けられていた空白ノードの名前に依存しなくなるわけです。
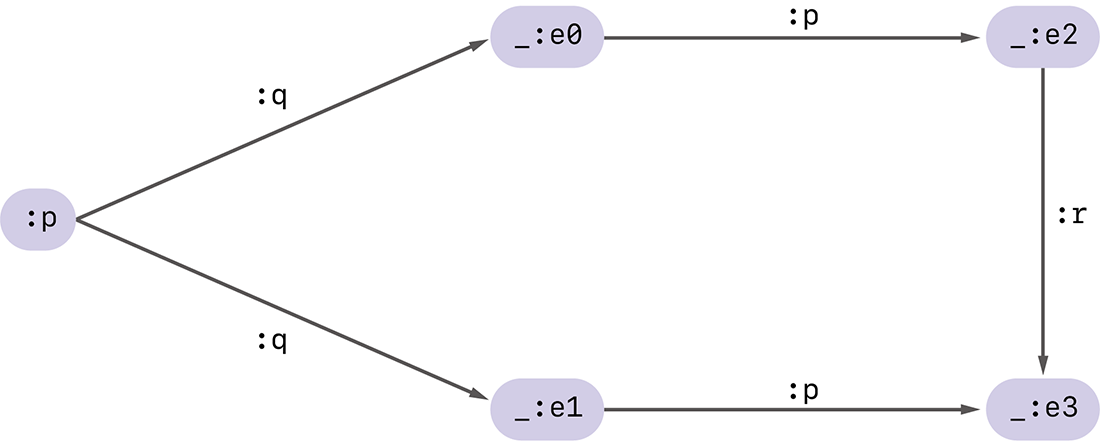
図-6の例のようにそこまで複雑ではないRDFグラフは、1次ハッシュの計算のみで正規化ができ、話は比較的簡単です。しかしRDFグラフによっては、異なる空白ノードに同じ1次ハッシュが割り当たってしまうことがあります。例えば図-7のようなグラフでは、空白ノードの周辺の状況がまったく同じような空白ノードが存在し、これらには同じ1次ハッシュが割り当たってしまいます。
実際、_:e0と_:e1を見てみると、これらはどちらも主語:pから述語:qを経て到達する目的語になっており、更にどちらも述語:pを介して空白ノードを目的語とする主語になっていることが分かります。この結果、これらの1次ハッシュ値はまったく同じ値になってしまいます。
そこでRDFC-1.0では、同じ1次ハッシュが割り当てられた空白ノードが存在する場合に限り、次なる識別手段としてn次ハッシュ(n-degree hash)を計算することになっています。n次ハッシュの計算方法はRDFC-1.0の中でも複雑な処理になっているため、本稿での説明は割愛します。興味のある方は仕様をご覧ください。
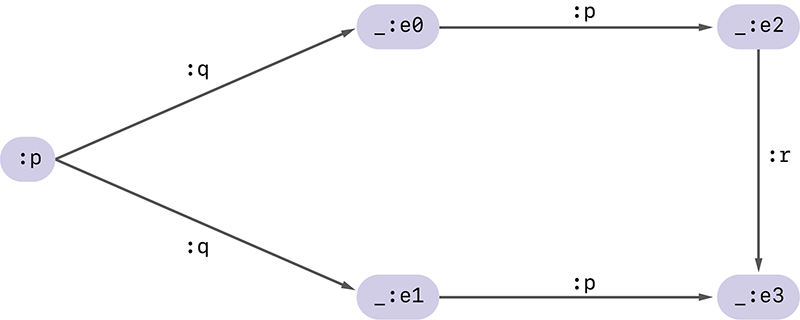
図-7 より複雑なRDFグラフの例
2.7 Canonicalizationの課題と対策
これまで見てきたように、RDF Dataset Canonicalizationの本質は空白ノードに順序付けをして正規化された名前を得ることにあります。従って、空白ノードを一切含まないRDFグラフのCanonicalizationでは、1次ハッシュやn次ハッシュの計算は必要なく、RDFグラフをN-Quadsとして表現した上でソートするだけの単純な処理(直列化)だけで済みます。
RDF Dataset Canonicalizationが必要以上に複雑な処理をしているとの誤解もありますが、Canonicaliationの複雑さは、入力されるRDFグラフに含まれる空白ノードの数と、空白ノードを含むグラフがどのような構造を持つかに依存して決まるものであって、実用上多くの場合、それらは単純な1次ハッシュ値計算のみで高速に終わることがほとんどです。
とはいえ、多くの空白ノードを含む特殊な構造を持つようなRDFグラフではn次ハッシュ値の計算に非常に長い時間を要するものも存在します(注19)。そこでRDFC-1.0の実装ではn次ハッシュの計算回数に上限を設け、上限を超えた場合にはエラーとして途中で終了させることが必須とされています。
また、RDFグラフがパーソナルデータや機密事項を含むような場合、正規化の結果からそれらが部分的に推測される可能性に注意が必要です。正規化の計算はグラフ内のデータに基づいて行われるため、正規化の結果作られた_:c14n0などの名前には、グラフ内の情報が部分的に含まれてしまいます。
例えばAliceの配偶者がBobであることを意味する、図-8のようなRDFグラフがあったとします。そしてこのグラフの正規化を行い、デジタル署名をつけて図-9のように保存したとします。
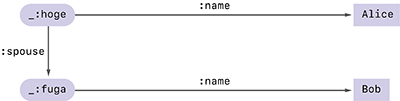
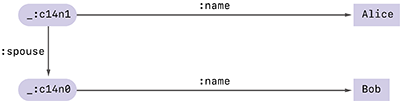
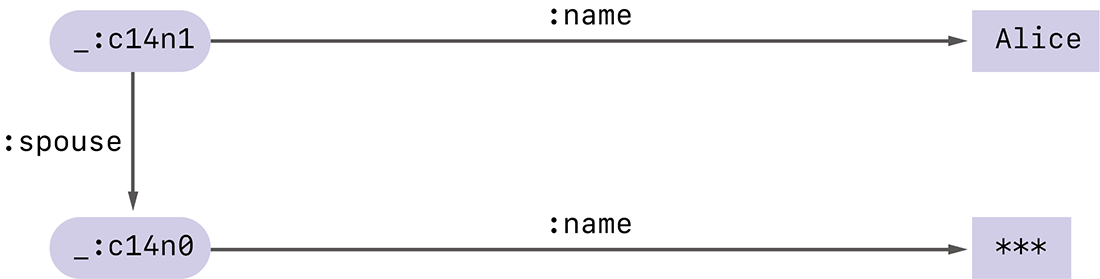
あるとき、何らかの理由でAliceは配偶者の名前を隠したまま、自身が結婚をしているという事実のみを表現したいと思ったとします。Verifiable Credentialの選択的開示という手法を使うと、デジタル署名の有効性を保ったまま配偶者の名前を隠し、図-10のような検証可能なRDFグラフを作ることができます。
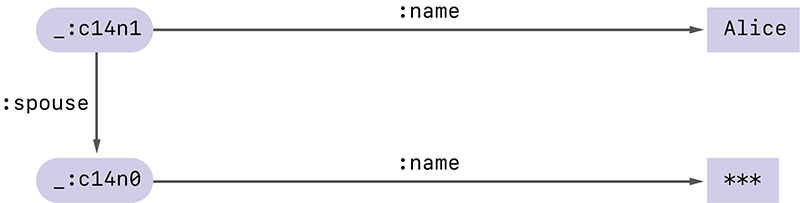
図-10 Bobの名前が隠されたRDFグラフ
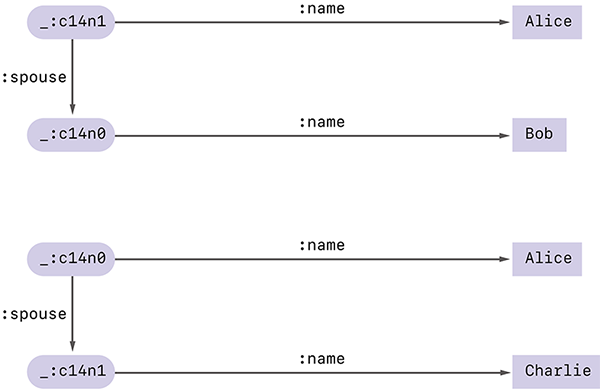
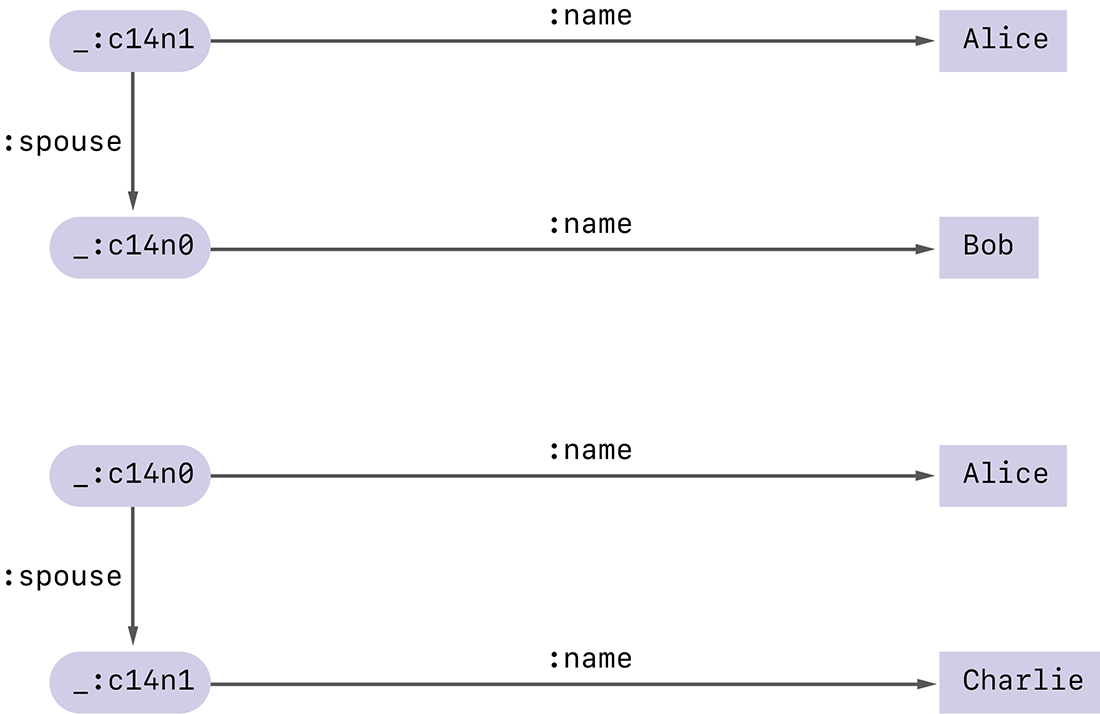
しかしこのグラフを見た人が、Aliceの配偶者はBobかCharlieのどちらかであるということまでは知っていたとします。そして***として隠されている部分にBobとCharlieの名前を入れて再び正規化をしたところ、図-11のように、正規化ラベルが異なる2つの結果が得られたとします。これらをAliceの公開したグラフと比較すれば、Aliceの配偶者はBobであったと特定することが可能になります。
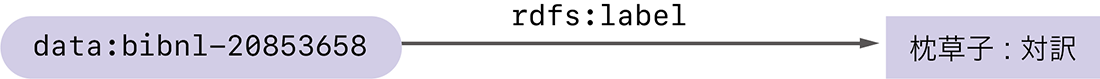{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
図-11 2つの異なる結果
これは特殊な状況を想定したものですが、Verifiable Credentials でRDF Dataset Canonicalizationを使う場合には注意すべき性質になります。そこで、W3C Verifiable Credentials Data Integrity(注20)という、Verifiable Credentialsのセキュリティやプライバシーを保護するための仕様の中で、こうした問題の回避について議論がなされています。
2.8 おわりに
以上、筆者がW3Cで標準化に協力し、W3C勧告となったRDF Dataset Canonicalizationについて、仕様と標準化活動の概要を紹介しました。RDF Dataset Canonicalizationを使うことで、RDFグラフの差分計算や更新の確認、更にはハッシュ値の計算やデジタル署名の生成も容易になります。これによりデータ管理が効率化され、RDFグラフに偽造耐性や真正性を持たせることも可能となります。私自身もこの仕様の一利用者として、Verifiable Credentialsやそのアプリケーションの研究開発に活用しています。本稿が皆様にも興味や関心をもっていただくきっかけとなれば幸いです。
- (注1)Dave Longley, Gregg Kellogg, Dan Yamamoto: RDF Dataset Canonicalization. W3C Recommendation, 2024/05/21.(https://www.w3.org/TR/rdf-canon/)。
- (注2)Richard Cyganiak, David Wood, Markus Lanthaler: RDF 1.1 Concepts and Abstract Syntax. W3C Recommendation, 2014/02/25.(https://www.w3.org/TR/rdf11-concepts/)。
- (注3)Olaf Hartig, Pierre-Antoine Champin, Gregg Kellogg, Andy Seaborne: RDF 1.2 Concepts and Abstract Syntax. W3C Working Draft, 2024/05/02(https://www.w3.org/TR/2024/WD-rdf12-concepts-20240502/)。
- (注4)ジャパンサーチ(https://jpsearch.go.jp/)。
- (注5)Dan Brickley, R.V. Guha: RDF Schema 1.1. W3C Recommendation, 2014/02/25(https://www.w3.org/TR/rdf11-schema/)。
- (注6)正確には、URLを一般化したInternationalized Resource Identifier(IRI)が使われます。
- (注7)この例では目的語がURLではなくただの文字列で表現されていますが、目的語にURLを取るトリプルも一般的です。
- (注8)Gregg Kellogg, Pierre-Antoine Champin, Dave Longley: JSON-LD 1.1. W3C Recommendation, 2020/07/16.(https://www.w3.org/TR/json-ld11/)。
- (注9)"c14n" は"canonicalization"の省略形です。
- (注10)一般にN-Quads形式のデータはソートされている必要はなく、また区切りとしての空白文字や改行文字の個数に制限はないですが、ここでは辞書順にソートした上で、区切り文字は1つになるよう制限を加えたものを用います。これはCanonical N-Quadsと呼ばれます。
- (注11)Internet Infrastructure Review vol.52「2. フォーカス・リサーチ(1) Verifiable CredentialとBBS+署名」(https://www.iij.ad.jp/dev/report/iir/052/02.html)。Vol.52で言及していた「LD Canonicalization」が、本稿で紹介するRDF Dataset Canonicalizationの旧称です。
- (注12)Phil Archerによるメール(https://lists.w3.org/Archives/Public/semantic-web/2024May/0030.html)。
- (注13)W3C RDF Dataset Canonicalization and Hash Working Group(https://www.w3.org/groups/wg/rch/)。
- (注14)RDF Dataset Canonicalization and Hash Working Group Charter(https://w3c.github.io/rch-wg-charter/)。
- (注15)Dan Yamamoto, Yuji Suga, Kazue Sako: Formalising Linked-Data based Verifiable Credentials for Selective Disclosure. 2022 IEEE European Symposium on Security andPrivacy Workshops (EuroS&PW)(https://doi.org/10.1109/EuroSPW55150.2022.00013)。
- (注16)Gregg Kellogg: RDF Dataset Canonicalization and Hash 1.0 Processor Conformance.(https://w3c.github.io/rdf-canon/reports/)。
- (注17)zkp-ld/rdf-canon(https://github.com/zkp-ld/rdf-canon)。
- (注18)正確にはUnicode Codepointの順序に従って整列させます。
- (注19)仕様ではこれらをPoison Datasetと呼んでいます。RDFグラフのCanonicalizationはグラフ同型問題という難しい問題と同じ難しさを持つことが分かっているため、入力によって非常に長い計算時間を要するのは避けがたい課題です。
- (注20)Manu Sporny, Dave Longley, Greg Bernstein, Dmitri Zagidulin, Sebastian Crane: Verifiable Credential Data Integrity 1.0. W3C Candidate Recommendation Draft, 2024/04/28.(https://www.w3.org/TR/2024/CRD-vc-data-integrity-20240428/)。
執筆者プロフィール

山本 暖(やまもと だん)
IIJ セキュリティ本部 セキュリティ情報統括室 シニアエンジニア。
2021年より現職。デジタルアイデンティティと情報セキュリティに関わる調査・研究活動に従事。
- 2. フォーカス・リサーチ(1)
W3C標準化活動:RDF Dataset Canonicalization
ページの終わりです